RobustSAM: Segment Anything Robustly on Degraded Images
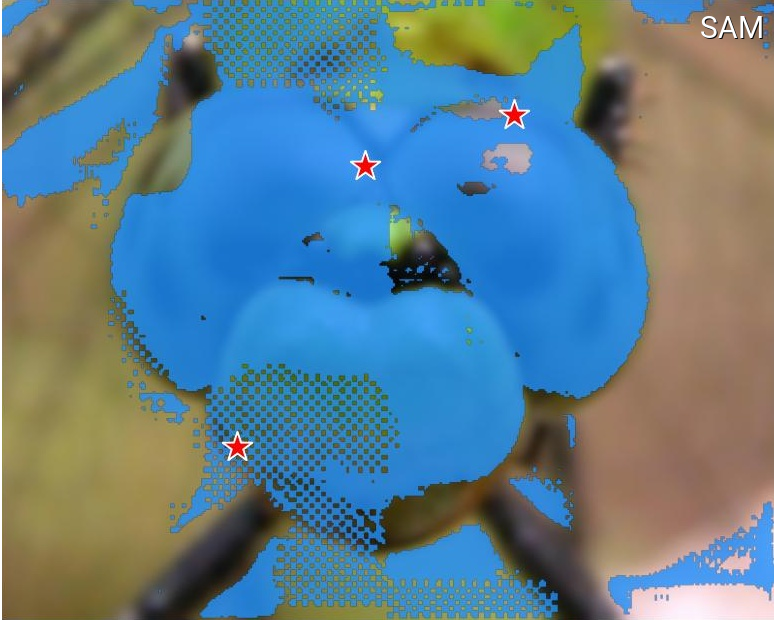



RobustSAM outperforms with precise boundaries and intact structures, where SAM falters with errors and fragmentation. Red star points and bounding boxes are our examples' input prompts.
Abstract
Segment Anything Model (SAM) has emerged as a transformative approach in image segmentation, acclaimed for its robust zero-shot segmentation capabilities and flexible prompting system. Nonetheless, its performance is challenged by images with degraded quality. Addressing this limitation, we propose the Robust Segment Anything Model (RobustSAM), which enhances SAM's performance on low-quality images while preserving its promptability and zero-shot generalization.
Our method leverages the pre-trained SAM model with only marginal parameter increments and computational requirements. The additional parameters of RobustSAM can be optimized within 30 hours on eight GPUs, demonstrating its feasibility and practicality for typical research laboratories. We also introduce the Robust-Seg dataset, a collection of 688K image-mask pairs with different degradations designed to train and evaluate our model optimally. Extensive experiments across various segmentation tasks and datasets confirm RobustSAM's superior performance, especially under zero-shot conditions, underscoring its potential for extensive real-world application. Additionally, our method has been shown to effectively improve the performance of SAM-based downstream tasks such as single image dehazing and deblurring.
Architecture of RobustSAM
The key contribution of RobustSAM is the Anti-Degradation Output Token Generation (AOTG) and Anti-Degradation Mask Feature Generation (AMFG) modules, which extract degradation-invariant information that is aligned those extracted from clear images by the original SAM.
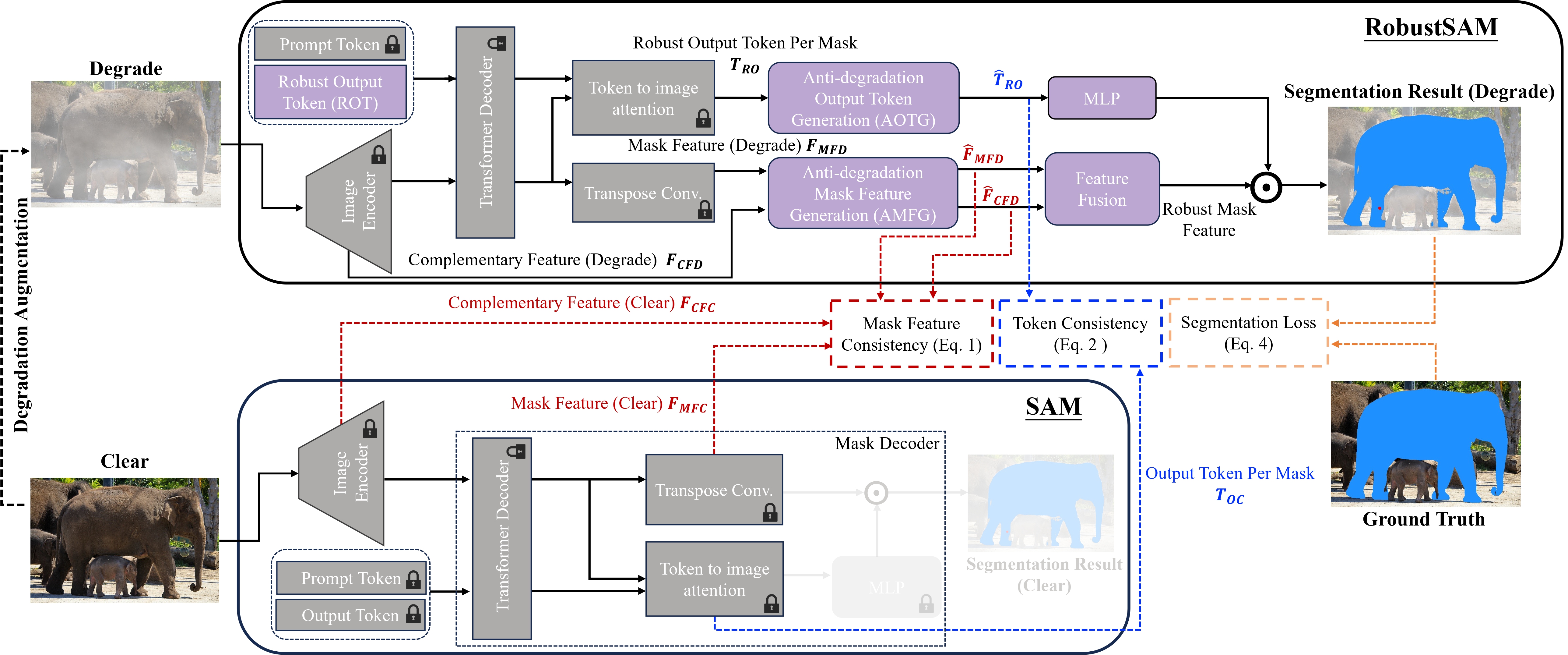
RobustSAM augments the original SAM by incorporating five essential components (in purple). During training, clear images are fed through the original SAM modules (in gray) to produce features for clear scenes. Subsequently, degraded images, generated through augmentation of clear inputs, are processed by RobustSAM, yielding features for degraded scenarios. These are then refined via Anti-degradation modules, ensuring consistency with features from clear scenes. This methodology, supported by a segmentation loss, achieves precise segmentation outcomes in both clear and degraded image conditions. During inference, only RobustSAM is used to predict a segmentation mask from an input image. Note: The prompt encoder is excluded for conciseness, and the padlock icons represent fixed components loaded from the original SAM model that are not updated during training.
Overview of the proposed AMFG and AOTG modules
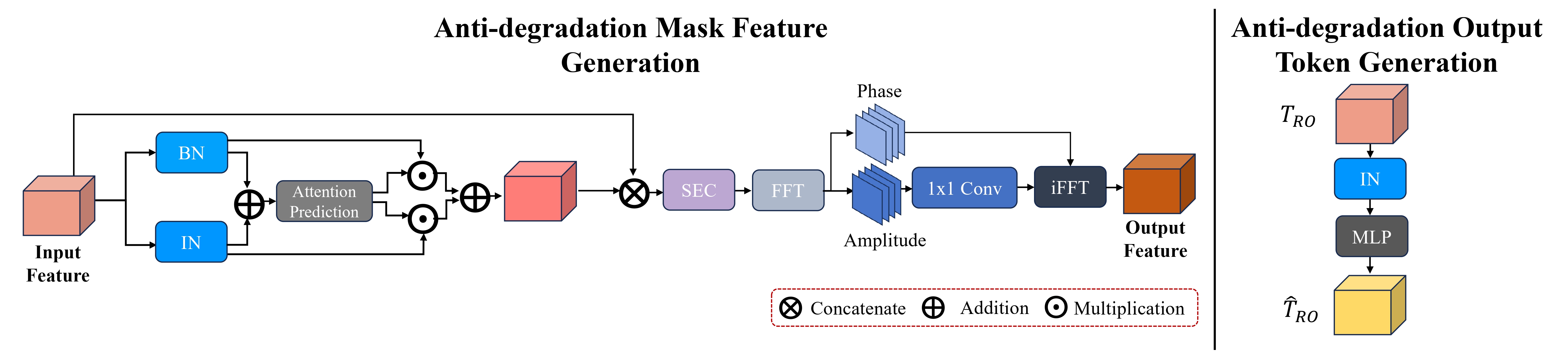
The Anti-Degradation Mask Feature Generation and Output Token Generation modules significantly enhance image quality and segmentation by normalizing degradation effects while preserving essential content. Utilizing Instance and Batch Normalization, the model stabilizes content under various conditions. A Fourier Degradation Suppression module further isolates degradation, focusing on maintaining structural integrity. These modules ensure the generation of robust, degradation-invariant features for precise image assessment and segmentation.
BibTeX
@inproceedings{chen2024robustsam,
author = {Chen, Wei-Ting and Vong, Yu-Jiet and Kuo, Sy-Yen and Ma, Sizhou and Wang, Jian},
title = {RobustSAM: Segment Anything Robustly on Degraded Images},
journal = {CVPR},
issue_date = {2024}
}